

Robots.txt désigne un fichier au format texte qui permet au webmaster ou à l’administrateur d’un site internet d’indiquer aux robots (également appelés crawlers) des moteurs de recherche les informations qu’ils sont autorisés à analyser. Il est exclusivement à destination des robots d’indexation, il n’interdit pas l’accès d’une page ou d’un répertoire à un internaute.

L’origine du fichier robots.txt
On attribue la paternité de ce fichier à Martin Koster qui travaillait pour Webcrawler en 1994. Il s’agissait à l’époque de réguler le crawl des robots, une activité qui avait la faculté d’occasionner un certain nombre de désagréments, comme l’activation de scripts et le plantage des serveurs.
Quel lien entre robots.txt et SEO ?
Le référencement d’un site web n’est pas possible sans l’exploration des contenus par les robots des moteurs. En leur donnant des consignes par l’intermédiaire de ce fichier, vous pouvez essentiellement leur expliquer qu’ils n’a pas vocation à s’intéresser aux contenus dont vous pensez qu’ils n’apporteraient aucune valeur ajoutée dans les résultats de Google, Bing ou encore Yahoo.
La création du robots.txt garantit-elle un meilleur référencement ?
En 2017, ce même moteur a communiqué à ce sujet. La facilité de crawl n’est pas un critère de pertinence de son algorithme, l’effet sur le SEO n’est donc pas mécanique, ceci étant une plateforme qui est explorée plus “efficacement” à évidemment davantage d’opportunités de voir ses meilleurs contenus analysés et donc restitués dans les SERPs.
Quels contenus interdire dans une optique de référencement ?
En premier lieu, les pages statiques que vous êtes en train d’actualiser pour des questions de pertinence peuvent faire partie des contenus que vous n’aimeriez pas voir analysés par les robots.
Ce sont également les informations qualifiées de confidentielles, comme des ressources non sensibles, mais avant tout destinées à être découvertes par des collaborateurs en interne (documentation, livre blanc, cahier des charges…) Nous pensons ensuite aux pages dupliquées, qui représentent fréquemment des parties de site importantes sur WordPress et d’autres SMS. Ce sont en outre les recherches du moteur de recherche interne, qui, si elles peuvent vous donner quelques idées pertinentes à exploiter en matière de référencement naturel, ne sont pas forcément intéressantes pour les utilisateurs de moteurs.
Quelles sont les autres règles relatives au référencement à connaître ?
Le nom de ce fichier doit forcément s’écrire de cette façon, au pluriel : robots.txt. Toute faute d’orthographe le rendra inutile. Quand un site internet bénéficie bien d’un fichier robots.txt mais qu’il ne peut pas être interprété par Google pour diverses raisons, alors le robot s’arrête d’accomplir sa fonction de crawl de l’adresse et de tous ses contenus. Autant dire que si vous décidez de bien intégrer le robots.txt, il doit être accessible, lisible et indiquer des consignes que les robots sont capables d’assimiler sous peine de ne plus explorer (donc indexer) les nouvelles informations que vous proposez aux internautes. Si l’URL de votre boutique ecommerce ou de votre site à caractère informatif apparaît déjà dans les résultats des moteurs, en interdire l’accès par le biais d’une consigne dans le robots.txt ne changera rien : l’URL restera en effet indexée. Au contraire, pour la désindexer, il faut autoriser son crawl et utiliser une balise meta robots noindex ou un entête HTTP X-Robots-Tag. L’alternative consiste à demander sa suppression dans Search Console. Il ne peut y avoir qu’un seul robots.txt et il doit absolument faire moins de 500 ko ou exactement 500 ko, un poids supérieur et une partie des consignes du fichier ne seront pas prises en compte. Le fichier robots.txt est aussi susceptible d’être indexé dans Google ou un autre moteur. Pour le désindexer, vous devez soit tirer profit d’un outil comme X-Robots-Tag ou interdire le crawl du fichier puis le faire supprimer de l’index dans Search Console. Par ailleurs, on recommande la création d’un fichier robots.txt pour chaque sous-domaine et pour chaque protocole (HTTP et HTTPS). Dans le cas où vous n’avez pas de consignes à formuler, rien ne vous empêche de laisser en ligne un fichier vide.
Comment utiliser, placer et mettre à jour le fichier robots.txt ?
Comment peut-on créer ou lire le robots.txt ?
Le fichier peut être créé et modifié aisément avec un simple éditeur de texte, à l’instar de Notepad, Atom ou Bloc-notes.
Où placer le fichier robots.txt ?
Le fichier robots.txt doit nécessairement se situer à la racine du site. Pour cela, il suffit de le glisser à l’emplacement prévu sur votre serveur FTP.
Comment le mettre à jour ?
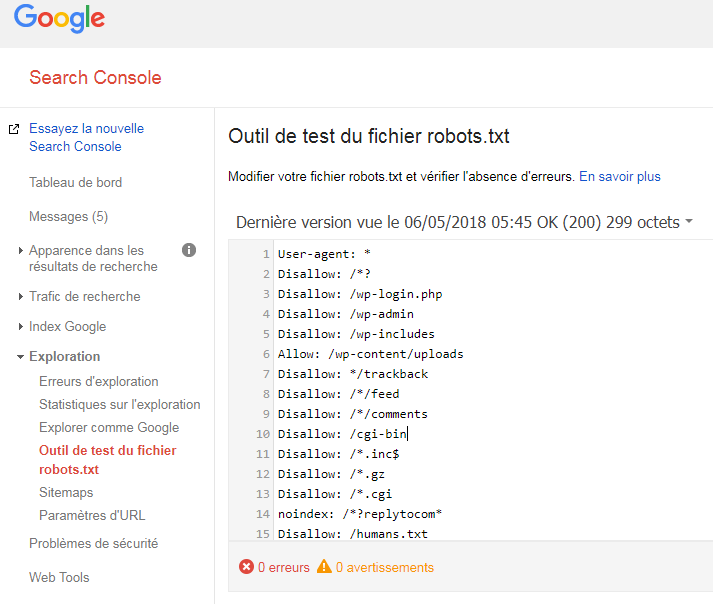
Dans la Search Console, chaque webmaster a la possibilité de mettre à jour le fichier robots.txt. Dans l’onglet “Exploration”, on distingue notamment la catégorie nommée “Outil de test du fichier robots.txt”. À cet endroit, il vous est par exemple permis de tester l’éventuel blocage d’une page. En cliquant sur “Envoyer”, suivez les consignes de Google pour actualiser votre fichier, il en tiendra compte assez rapidement.
Pour visualiser votre fichier, tapez simplement dans votre barre d’adresse de navigateur l’URL sous cette forme : https://www.monsite.fr/robots.txt
Robots.txt : ce qu’il ne faut surtout pas faire
- Un changement d’URL du robots.txt (qui ne se trouve plus à la racine)
- l’URL du robots.txt qui renvoie une erreur (404, 500…)
- Le robots.txt écrasé par la version en préproduction (dans laquelle est mentionnée une directive disallow/ qui bloque tout le site)
- Une ligne blanche dans un bloc de directives
- Un mauvais encodage du fichier (il doit être en UTF-8)
- Un mauvais ordre des blocs de directives
Les commandes du robots.txt
Autoriser l’indexation de toutes les pages d’un site
1ère méthode
User-agent: *
Disallow:
On ne met rien après le « Disallow: », ce qui signifie qu’on ne bloque rien.
2ème méthode
User-agent: *
Allow: /
Ici, on autorise les robots à indexer toutes les pages.
Bloquer l’indexation de toute les pages
User-agent: *
Disallow: /
Bloquer l’indexation d’un dossier en particulier
User-agent: *
Disallow: /dossier/
Bloquer GoogleBot dans l’indexation d’un dossier, sauf pour une page spécifique dans ce dossier
User-agent: Googlebot
Disallow: /dossier/
Allow: /dossier/nompage.html




